Автор: Моркун В.С., Цвиркун С.Л.
Категории:
автоматизация
В статье рассмотрены методы кластерного анализа для определения типов крупнокусковой руды в потоке на конвейерной ленте, для последующей сортировки отдельных кусков с высоким содержанием железа
Ключевые слова: железорудное сырье, кластер, алгоритм классификации, нечеткая кластеризация.
Исследование методов нечеткой кластеризации для определения типов руды

Моркун Владимир Станиславович
д.т.н., проф. и.о. проректора с научной работы ГВУЗ "Криворожский национальный университет"

Цвиркун Сергей Леонидович
"Криворожский национальный университет"
Для обеспечения высоких технико-экономических показателей добычи и переработки минерального сырья необходимо управлять качеством еще в стадии планирования, добычи и транспортировки руд. Поскольку принадлежность рудного материала к определенной разновидности может быть определена по нескольким характеристикам, то для выполнения этой операции целесообразно использовать операцию кластеризации.
Большинство алгоритмов кластеризации не опираются на традиционные для статистических методов допущения; они могут использоваться в условиях почти полного отсутствия информации о законах распределения данных [1].
Исходной информацией для кластеризации является матрица измерения косвенных признаков технологических разновидностей руды, состоящая из n строк, каждая из которых содержит значения признаков отдельной пробы:
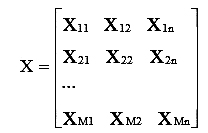 (1)
(1)
где n – количество признаков; M – количество проб руды. В данном случае, задачей является разбиение проб руды, представленной несколькими технологическими разновидностями на несколько кластеров, схожесть проб в которых позволяет выделить определенную технологическую разновидность.
Для осуществления кластеризации характеристик проб руды рассмотрим методы нечеткой кластеризации.
В реальной ситуации разделение рудного материала на технологические разновидности сложно представить двумя степенями принадлежности 0 или 1. Более естественным является использование частичной принадлежности в диапазоне от 0 до 1, что позволит пробам руды, характеристики которых находятся на границах между несколькими кластерами, принадлежать им с разной степенью. [1]
Алгоритм кластеризации Fuzzy C-means, использовавшийся для кластеризации характеристик проб руды, основан на минимизации функционала C-means [1, 3]
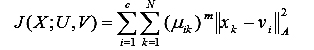 (2)
(2)
вектор центров кластеров
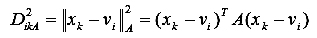 (3)
(3)
Результат кластеризации проб железорудного сырья, выполненной по алгоритму Fuzzy C-means, рис. 1, показал правильное, в сравнении с эталоном определение центров кластеров, что позволяет сделать вывод о перспективности использования данного метода.
Также, для классификации характеристик железорудного сырья был использован алгоритм Густафсона-Кесселя (Gustafson-Kessel), который совершенствует Fuzzy C-means алгоритм, используя адаптивную норму расстояния [4] для каждого кластера
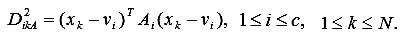

Рис. 1. Результат Fuzzy C-means кластеризации проб железорудного сырья
Целевая функция алгоритма определяется следующим образом
 (4)
(4)
Результат кластеризации проб железорудного сырья для определения типов руды, выполненной по алгоритму Густафсона-Кесселя приведен на рис. 2.

Рис. 2. Результат кластеризации Густафсона-Кесселя проб железорудного сырья
В развитие работы [4] Гас и Гева (Gath, Geva) в работе [5] сформировали новую функцию расстояния на основе нечетких оценок максимального правдоподобия
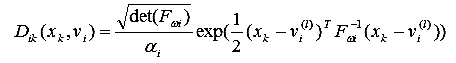 (5)
(5)
Результат кластеризации проб железорудного сырья, выполненной по алгоритму Гаса-Гева приведен на рис. 3.

Рис. 3. Результат кластеризации Гаса-Гева проб железорудного сырья
Оценка качества кластеризации была проведена с использованием следующих скалярных мер достоверности.
Коэффициент распределения (РС): измеряет величину «перекрытия» между кластерами [3]
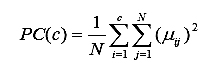 (6)
(6)
где mij – функция принадлежности точки данных j в кластере i. Максимальному значению функционала соответствует оптимальное количество кластеров.
Энтропия классификации (CE) является мерой нечеткости распределения
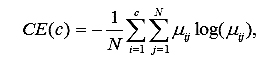 (7)
(7)
Показатель распределения (SC) представляет собой отношение суммы компактности и разделения кластеров [6].
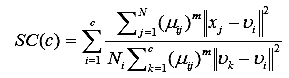 (8)
(8)
Меньшее значение SC соответствует лучшему результату кластеризации.
Показатель разделение (S) [6].
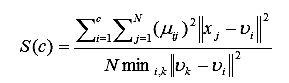 (9)
(9)
Показатель Xie-Beni (XB) определяет количественную оценку соотношения полной вариации в кластерах и разделение кластеров [7]
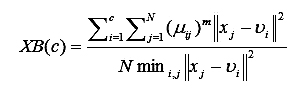 (10)
(10)
Оптимальному количеству кластеров для определения типов руды соответствует минимальное значение показателя.
Показатель Данна (Dunn's Index, DI): используют для выявления «компактных и хорошо разделенных кластеров» [2]
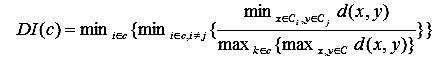 (11)
(11)
Альтернативный показатель Данна (Alternative Dunn Index, ADI)
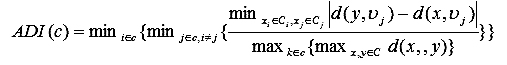 (12)
(12)
Результаты сравнения методов кластеризации по рассмотренным выше показателям для определения типов руды приведены в табл. 1
Таблица 1
Результаты сравнения методов кластеризации
|
|
PC
|
CE
|
SC
|
S
|
XB
|
DI
|
ADI
|
|
FCM
|
0.6984
|
0.6996
|
0.5178
|
0.0044
|
4.5559
|
0.2443
|
0.0003
|
|
GK
|
0.7111
|
0.6681
|
0.5034
|
0.0043
|
5.5842
|
0.2443
|
0,0001
|
|
GG
|
0.9940
|
0.0118
|
1.1264
|
0.0098
|
1.7113
|
0.2443
|
0.0090
|
Наилучшие показатели имеют методы Густафсона-Кесселя и Гаса-Гева. Однако, недостатком алгоритма Гаса-Гева является необходимость предварительной обработки исходных данных путем кластеризации с использованием, например, метода нечеткой кластеризации FCM. Таким образом, наиболее целесообразным представляется использование метода нечеткой кластеризации Густафсона-Кесселя.
References
1. Shtovba S.D. Vvedeniye v teoriyu nechetkikh mnozhestv i nechetkuyu logiku / S.D. Shtovba . - Rezhim dostupa: // HTTP : MATLAB / exponenta.ru / fuzzylogic / book1.
2. Balasko B. Fuzzy Clustering and Data Analysis Toolbox / Balasko B., Abonyi J., Feil B. – 74 p.
3. Bezdek J. C. Pattern Recognition with Fuzzy Objective Function Algorithms. Plenum Press, 1981.
4. Gustafson D.E., Kessel W.C. Fuzzy clustering with a fuzzy covariance matrix // Proc. IEEE CDC, San Diego, CA. — 1979. — P. 761 - 766. - Vol. 7. - P. 773 - 781.
5. Gath I., Geva A.B. Unsupervised optimal fuzzy clastering// IEEE Trans. Pattern Anal. Machine Intell., 1989. — Vol. 7. - P. 773 - 781.
6. Bensaid A.M., Hall L.O., Bezdek J.C., Clarke L.P., Silbiger M.L., Arrington J.A., Murtagh R.F. Validity-guided (Re)Clustering with applications to imige segmentation. IEEE Transactions on Fuzzy Systems, 4:112-123, 1996.
7. Xie X. L. and Beni G. A. Validity measure for fuzzy clustering. IEEE Trans. PAMI, 3(8):841{846, 1991.

